고정 헤더 영역
상세 컨텐츠
본문
오늘은 자바 Stream API를 oracle java docs 기반으로 살펴보고자 합니다.
A sequence of elements supporting sequential and parallel aggregate operations.
Stream은 '순차적 및 병렬적 집계 작업을 지원하는 일련의 요소' 입니다.
여기서 집계 작업(aggregate operation)은 Stream API가 제공하는 filter, map, reduce, find, match, sort 등으로 데이터를 조작하는 것을 말합니다. Stream은 집계 작업들을 손쉽게 순차적 및 병렬적으로 수행할 수 있도록 제공하고있고 이는 뒤에서 좀 더 자세히 알아보겠습니다.
In addition to Stream, which is a stream of object references, there are primitive specializations for IntStream, LongStream, and DoubleStream, all of which are referred to as "streams" and conform to the characteristics and restrictions described here.
또한 Stream은 기본형에 특화된 IntStream, LongStream, DoubleStream 을 제공합니다. 또한 각 인터페이스들은 기본형 타입과 관련된 sum, min, max 등 reduce 연산과 관련된 메소드를 제공합니다.
아래 예제는 각각 Stream과 Primitive Stream으로 age 합을 계산한 테스트 코드입니다.

두 방법 모두 연산의 결과는 동일하지만, Stream<Integer>의 경우 내부적으로 합계를 계산하기 전에 Integer를 기본형으로 unboxing 해야합니다. 이 때문에 Stream API는 IntStream과 같은 기본형 특화 스트림을 제공합니다.
Stream<Integer> boxed = intStream.boxed();IntStream은 boxed 메소드를 통해 간단히 일반 스트림으로 변형 할 수 있습니다.
To perform a computation, stream operations are composed into a stream pipeline. A stream pipeline consists of a source (which might be an array, a collection, a generator function, an I/O channel, etc), zero or more intermediate operations (which transform a stream into another stream, such as filter(Predicate)), and a terminal operation (which produces a result or side-effect, such as count() or forEach(Consumer)).
Streams are lazy; computation on the source data is only performed when the terminal operation is initiated, and source elements are consumed only as needed.
스트림은 파이프라인을 통해 연산을 수행합니다. 스트림 파이프라인은 연산을 수행할 객체(source)와 중간 연산(intermediate operations), 최종 연산(terminal operation)으로 구성됩니다.

중간 연산은(filter, map, limit ...) 항상 새로운 스트림을 리턴합니다.
물론 스트림은 lazy 하기 때문에 중간 연산마다 새로운 스트림을 생성하는 것이 아니라, 최종 연산 전의 모든 중간연산을 합친 후에 합쳐진 중간 연산을 최종 연산으로 처리합니다.

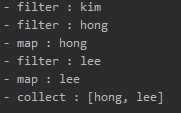
중간 연산을 filter, map, limit 순서로 나열하고 최종 연산 collect를 실행한 테스트 코드입니다.
보시다시피 age > 15 filter 조건을 만족하는 요소는 총 3개지만, 스트림의 lazy한 특성 때문에 2개만 선택되는 것을 보실 수 있습니다.
또한 위 예제를 통해 스트림이 source의 순서를 유지한다는 점도 알 수 있습니다.
Most stream operations accept parameters that describe user-specified behavior, such as the lambda expression.
To preserve correct behavior, these behavioral parameters:
- must be non-interfering (they do not modify the stream source); and
- in most cases must be stateless (their result should not depend on any state that might change during execution of the stream pipeline).
non-interfering > 스트림 파이프라인 내에서 스트림 요소의 수정이 발생하면 안됩니다.
stateless > 스트림 파이프라인의 결과가 파이프라인 내에서 변화하는 상태에 의존하면 안됩니다.
앞서 말한 두개의 behavior를 만족하지 않을 경우, parallel한 상황에서 예기치 못한 문제가 일어날 수 있습니다.

parallel한 상황이 아니더라도 Stream 요소의 수정이 발생하면 위와 같은 문제가 발생할 수 있습니다.
"one", "two"를 가진 List로 stream을 생성했지만, 최종 연산이 수행되기 전에 stream의 요소가 변경된다면 stream을 생성한 시점과는 다른 결과가 도출될 수 있습니다.
이와같은 side-effect를 방지하기 위해서는 새로운 collection을 생성하는 습관이 필요합니다.

Collections and streams, while bearing some superficial similarities, have different goals.
Collections are primarily concerned with the efficient management of, and access to, their elements.
By contrast, streams do not provide a means to directly access or manipulate their elements, and are instead concerned with declaratively describing their source and the computational operations which will be performed in aggregate on that source.
Stream과 Collection은 모두 연속된(순서를 유지하는) 요소의 값을 저장하거나 순회하는 자료구조의 인터페이스(forEach ..)를 제공하는 등 비슷하지만 서로 다른 목적을 가지고 있습니다.
Collection은 요소를 효율적으로 저장하고 관리(접근, 수정 등)하는데 초점을 맞추고 있습니다. 때문에 요소들을 Collection에 넣기 전에 계산하여 추가합니다.
이와 달리 Stream은 요소를 직접 접근하거나 수정하는 방법을 제공하지 않고, 데이터를 요청할 때만 값을 계산합니다.
Stream에 대해 조금 더 자세히 살펴보자면,
- No storage.
: Stream은 source를 저장하는 자료구조가 아니라, source로 파이프라인을 구성하여 연산의 결과를 전달합니다.
- Functional in nature.
: source를 수정하지 않고 연산의 결과를 생성해서 전달합니다.
- Possibly unbounded.
: Collection은 finite size이지만, Stream은 그렇지 않습니다.
- Consumable
: 한번 소비한 (최종 연산을 수행한) Stream은 다시 소비할 수 없습니다.
또한 Collection은 외부 반복 (명시적으로 컬렉션의 요소를 가져와서 처리), Stream은 내부 반복 (내부적으로 스트림이 반복을 알아서 처리)이라는 차이점이 있습니다.
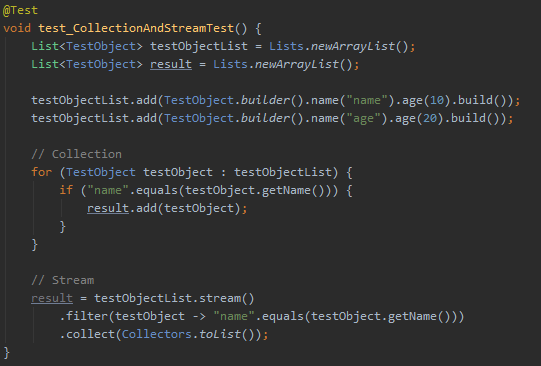
However, if the provided stream operations do not offer the desired functionality, the BaseStream.iterator() and BaseStream.spliterator() operations can be used to perform a controlled traversal.
물론 BaseStream.iterator() 혹은 .forEach 등을 사용해 Stream의 내부반복을 외부반복으로 변환할 수 있습니다.
Iterator<TestObject> iterator = testObjectList.stream().iterator();
while (iterator.hasNext()) {
TestObject testObject = iterator.next();
if ("name".equals(testObject.getName())) {
result.add(testObject);
}
}
A stream should be operated on (invoking an intermediate or terminal stream operation) only once. This rules out, for example, "forked" streams, where the same source feeds two or more pipelines, or multiple traversals of the same stream. A stream implementation may throw IllegalStateException if it detects that the stream is being reused. However, since some stream operations may return their receiver rather than a new stream object, it may not be possible to detect reuse in all cases.
일반적으로 스트림은 Consumable 합니다.
한 번 소비한(invoking an intermediate or terminal stream operation) 스트림을 재사용 하려한다면 Exception이 발생합니다.

본문에 나온 예제들은 깃에 올라가있습니다.
https://github.com/93Hong/Funtional-programming
93Hong/Funtional-programming
Contribute to 93Hong/Funtional-programming development by creating an account on GitHub.
github.com
<참고자료>
- Oracle java doc > https://docs.oracle.com/javase/8/docs/api/java/util/stream/Stream.html
- Modern java in action > https://book.naver.com/bookdb/book_detail.nhn?bid=13581948





댓글 영역